|
I am a fourth-year undergraduate of Department of Computer Science and Technology, Tsinghua University of China. My research interest includes generative models such as diffusion models, and their applications in (video) world models. Email / Google Scholar / GitHub / |
|
|
- [2024.09] 🎉 One paper: UltraViCo: Breaking Extrapolation Limits in Video Diffusion Transformers is accepted by ICLR 2026 as a poster.
- [2024.09] 🎉 One paper: RIFLEx: A Free Lunch for Length Extrapolation in Video Diffusion Transformers is accepted by ICML 2025 as a poster.
- [2024.09] 🎉 One paper: Identifying and Solving Conditional Image Leakage in Image-to-Video Diffusion Model is accepted by NeurIPS 2024 as a poster.
- [2024.05] 🎉 Our text-to-video model Vidu, which produces 16s clips with 1080p and is similar to Sora, has been published.
|
|
|
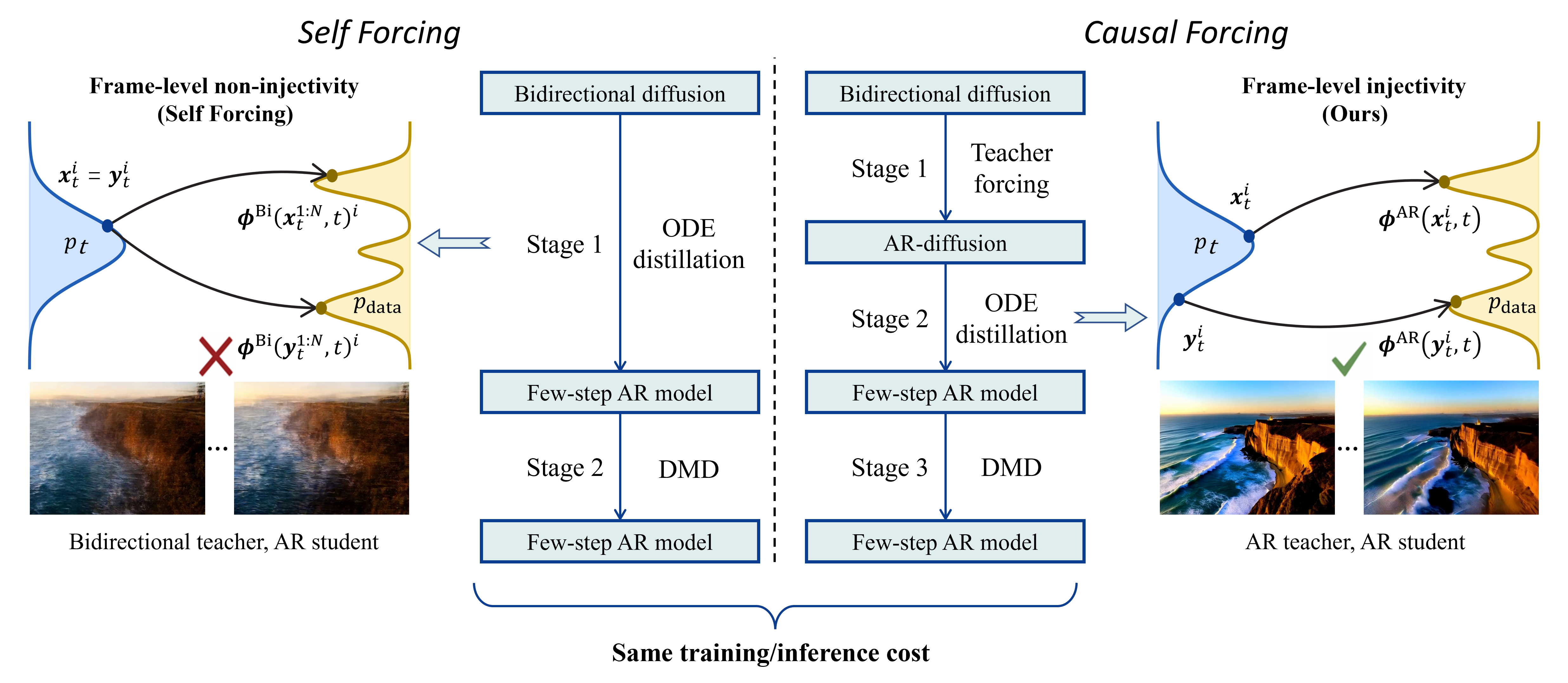
Hongzhou Zhu*, Min Zhao*, Guande He, Chongxuan Li, Jun Zhu † Arxiv Paper / Website / Code |
|
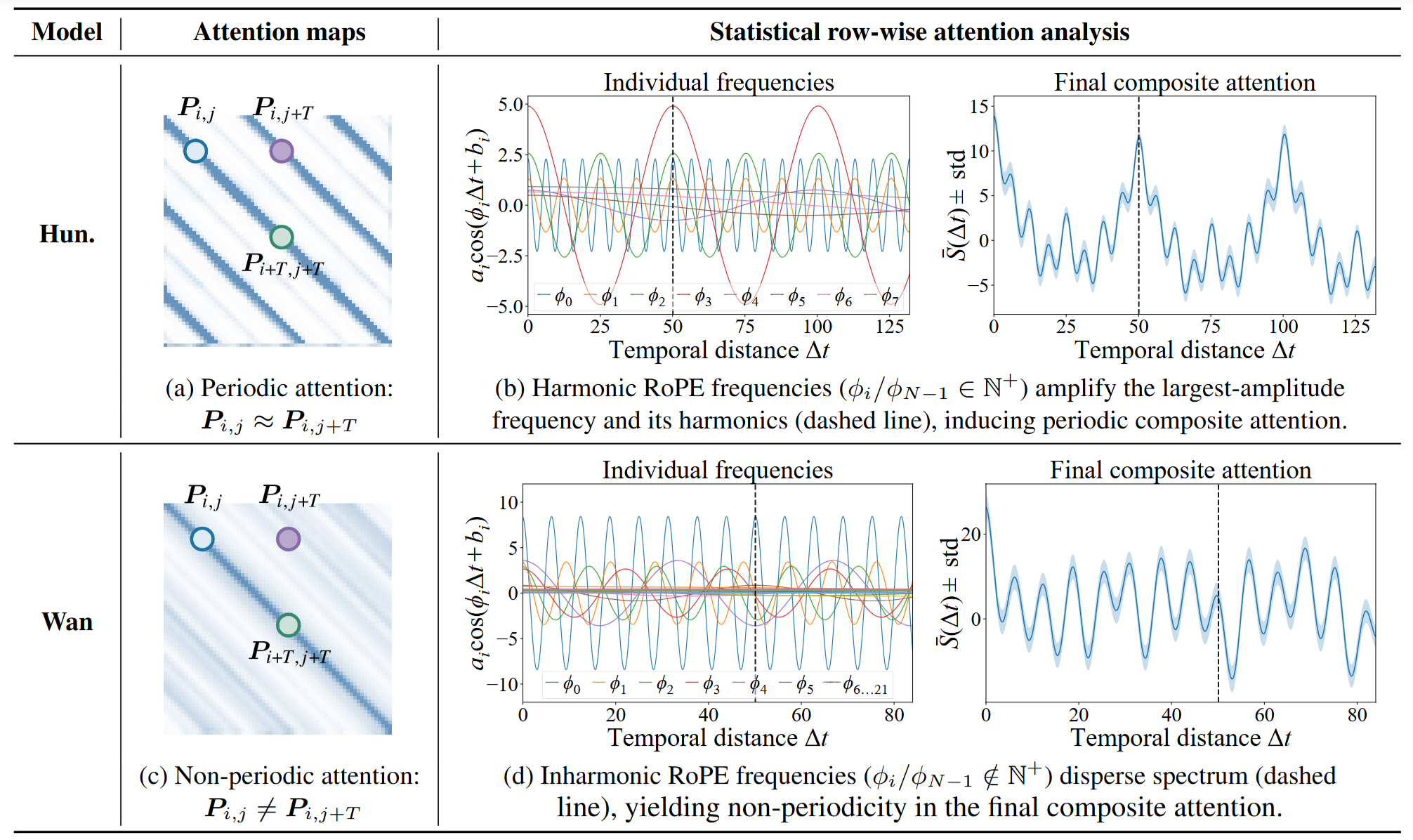
Min Zhao *, Hongzhou Zhu * , Yingze Wang, Bokai Yan, Jintao Zhang, Guande He, Ling Yang, Chongxuan Li Jun Zhu † ICLR 2026 Paper / Website / Code |

|
Min Zhao, Guande He, Yixiao Chen, Hongzhou Zhu, Chongxuan Li †, Jun Zhu † ICML 2025 Paper / Website / Code |
|
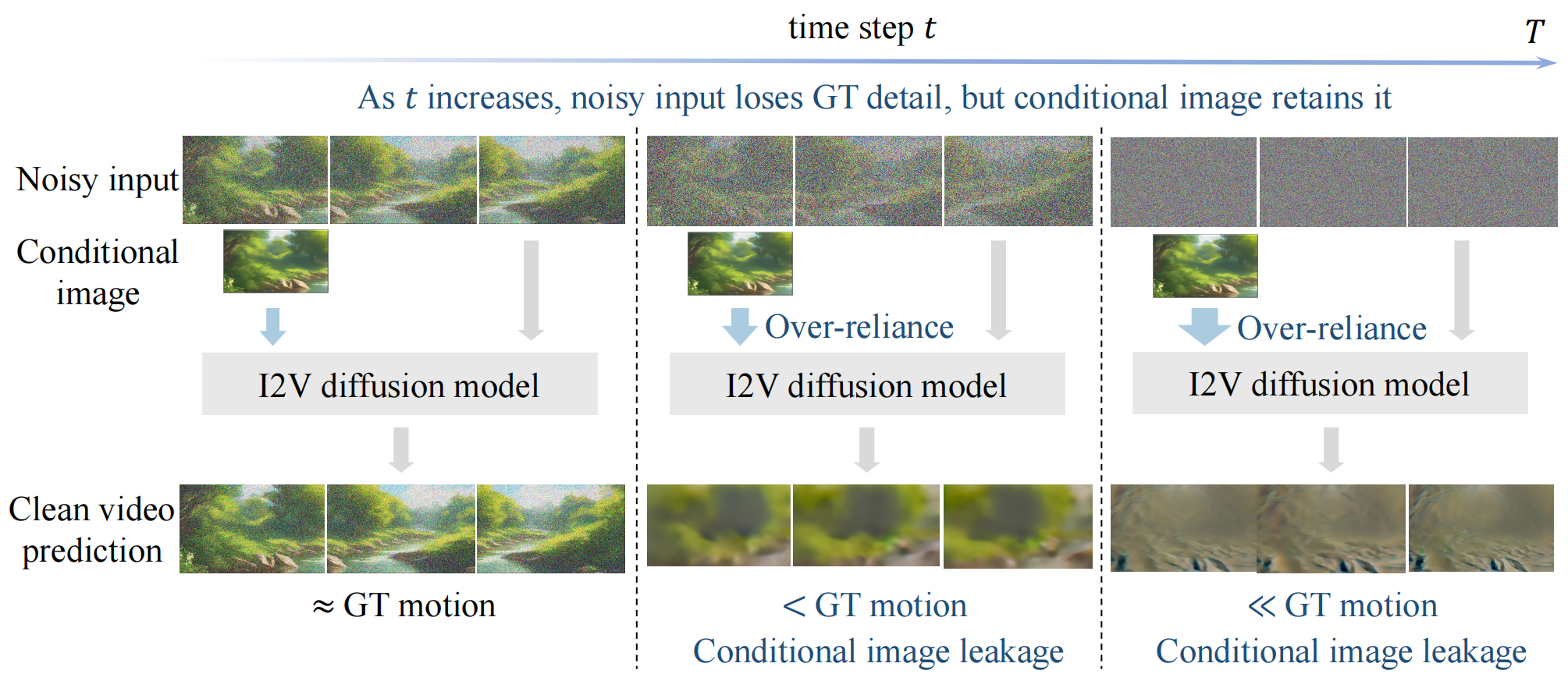
Min Zhao*, Hongzhou Zhu*, Chendong Xiang, Kaiwen Zheng, Chongxuan Li †, Jun Zhu † NeurIPS 2024 Paper / Website / Code / |

|
Fan Bao, Chendong Xiang*, Gang Yue*, Guande He*, Hongzhou Zhu*, Kaiwen Zheng*, Min Zhao*, Shilong Liu*, Yaole Wang*, Jun Zhu † Arxiv Paper / Website |